/ 8 min read
What makes an use case serverless?
Last Updated:
I have recently migrated the backend part of the web app for a cabinet of medics from a serverful to a serverless architecture. The reason for the migration was to optimize costs. Traffic patterns over the span of one year showed that having a web server up and running 24/7 - and paying it as such - was not worthwhile. Now, this is where serverless comes into play. Serverless’ promise is to only pay for what you actually use in terms of execution times. Having infrequent requests, the consideration was that it would be worth the migration.
A brief overview of Serverless
Serverless is first and foremost a pricing model. Contrary to what the name suggests, servers are involved, in fact many of them. Only the big cloud providers, who have a lot of idle compute resources and servers, can offer serverless at all. In contrast to serverful, the runtime environment is restarted with almost every invocation of its serverless app (a so-called function) and shut down again after a short time. The invocation of a serverless function comes with a so-called cold start-up time for the environment.1
In AWS Lambda (the serverless service of AWS), per default, the runtime stays up for 15 minutes after its initial invocation and would only be used by sequential subsequent function invocations within this timespan without spinning up a new environment. Concurrent invocations though always spin up new environments because serverless is single-threaded. It is this clear-cut approach of starting and terminating environments that enables payment by execution time.
Serverless functions are typically written in interpreted scripting languages like Python or JavaScript that do not involve virtual machines for their runtime environments. Starting such a virtual machine extends the cold start-up time and therefore the response time of a serverless function.2
Migrating from serverful to serverless
The old infrastructure of the web app’s backend consisted of a load balancer and two VMs, each hosting an instance of the backend. AWS Elastic Beanstalk (EBS) was used to provision all the infrastructure including IPs and all the other network parts that are needed to make an app accessible through the web. The backend spoke HTTP because it was a Spring Boot app that comes with an embedded Apache Tomcat web server. So, an instance of the backend would not only execute the business logic but also do all the web-related things like rate limiting, CORS, request validation, etc.
In order to turn a serverful web backend into serverless there would need to be alternatives for a majority of these functionalities in the serverless world.
Serverless related services
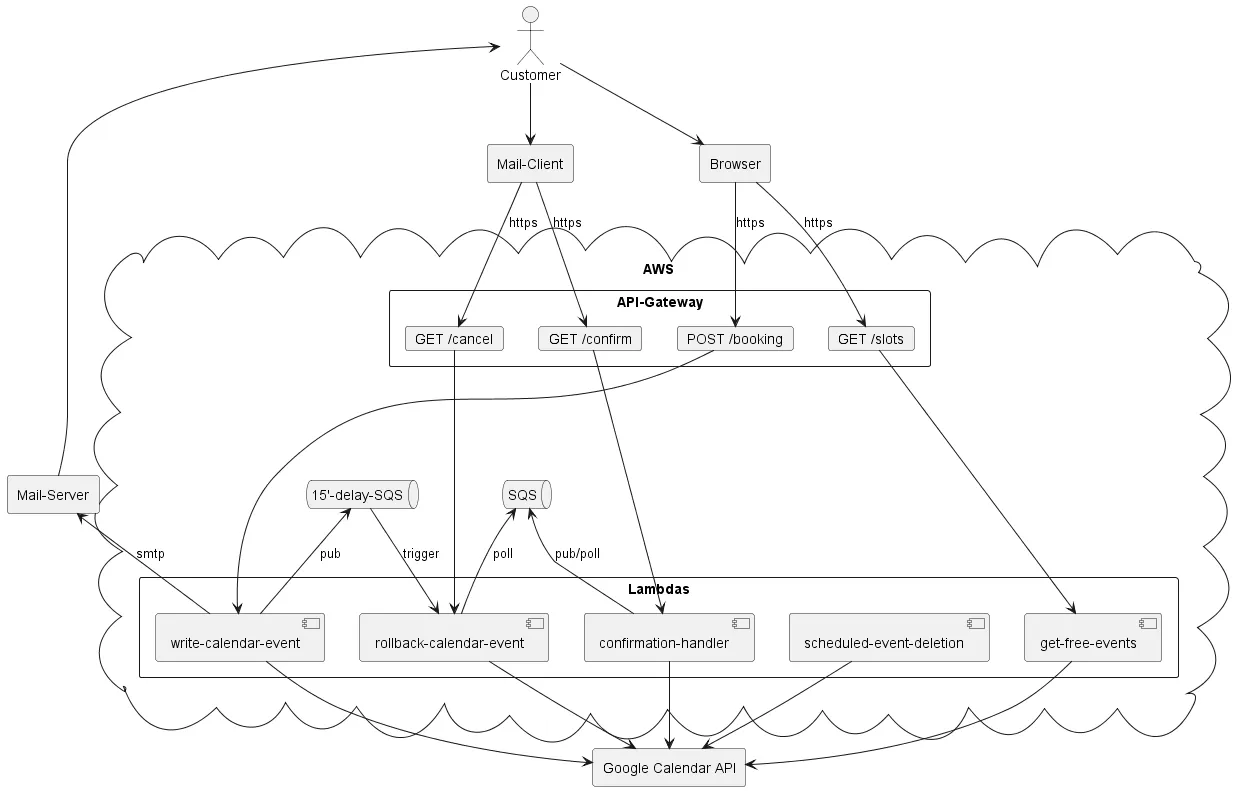
When making use of serverless in the context of a web app a serverless function has to be used in combination with other cloud services because a function cannot embody an entire web framework. Simply by virtue of its design serverless rejects the idea of a long running thread. This is where the first advantages and disadvantages come to light. Like hardly any other framework, serverless offers the opportunity to separate the business logic from other layers and to divide it into small functions each bounded by context. However, this can be a blessing and a curse at the same time, since, in contrast to the classic portable Java app, one is now getting more and more dependent on the cloud-specific services around a serverless function. In the AWS world API Gateway would be the go-to service that encapsulates all the web-related work and transforms a web request into an input argument for a serverless function.3
Serverless vs. Microservices
Serverless and Microservices both ought to be independently scalable small units of bounded contexts. As a matter of fact, one can think about serverless as a cloud-specific microservice implementation without the web server. Technically, in serverless one is forced to decouple services via message brokers way more than with serverful microservices because there is no remote protocol for function-to-function communication - which would be a very serverful approach anyway.4
With serverless I split the business logic of my then serverful application into five Lambdas, each having a bounded context: one for reading calendar events, one for making a reservation for an event, one for finalizing a booking of an event by confirming a reservation, another one for rolling back reservations and bookings and one for cleaning up outdated data. I would have never ever done this in serverful as it would have meant paying at least five server instances.
The now distributed, and therefore more complex nature of the application is secured as a functioning network by making use of two queues (AWS SQS) and API Gateway to trigger and message relay the business logic. Speaking about message relaying, the biggest difference between conventional message brokers5 and cloud-specific ones is that the latter can act as triggers to initialize other cloud-specific services. This is an unique and convenient attribute! In a classic microservice infrastructure one would need to have an app up and running to check for new messages. Hence, the convenience of serverless invites to consume more and more cloud-specific features to eventually get locked-in.
In my estimation, this is is exactly the reason why serverless has not yet become the predominant paradigm and a lot of cloud-ready enterprises rather host a portable Kubernetes in the cloud themselves than utilizing a convenient fully-managed service or going serverless.
Observability
One such convenient by-product of a serverless lock-in is observability. In fact, comfort with regards to monitoring was the first huge improvement I felt right from the get-go after having migrated to serverless. Wit AWS EBS I had to get the app logs out of the isolated VMs myself in order to have them monitored somewhere else more suitable. This is a task that a cloud provider cannot provide, of course, else there would be no isolation. With serverless as one of the cloud-specific services par excellence, log handling and monitoring is super integrated. Logs are by default forwarded to AWS CloudWatch, where one can easily build dashboards and set alarms.
Cost transparency
AWS is generally not known for providing a transparent billing experience. I have to say though, with serverless my costs gained a lot more transparency. The most obscure thing about AWS EBS was the pricing of the load balancer. Recall, my old architecture consisted of a load balancer and two VMs. A load balancer is just another VM running an application containing the load balancing logic - in this case written by AWS. On average, the load balancer cost me $20 per month but the two (!) other VMs $18 in total. AWS charges quite a lot for the service of provisioning a fully-managed load balancer, more than twice the amount of one of my VM instances.
There’s a price for a Lambda execution per millisecond that varies over the memory one configures for a Lambda to allocate. The min memory is 128MB, which should be enough for most of the use cases, and amounts to $0.0000000017 per 1ms (as of October 2022 with region eu-central-1 and arm64). Now it comes down to simple math: track the count of Lambda executions in a dashboard as well as the average execution time, the cost will be around that average time multiplied by the count and the price. Additionally, apply this procedure to API Gateway as it has a similar pricing model.
Conclusion
Lately, failed migrations and cost explosions made the news with regards to serverless - mostly due to scaling as costs scale when traffic scales until a break-even point is surpassed where the serverful alternative turns out to be cheaper. Having read through the bad news, my opinion is that these failed serverless experiences are rooted in bad load estimations and misinterpretations of the app’s traffic patterns. My migration was a success because my app showed serverless favorable traffic patterns. I am convinced that serverless is a great technology that can lead to a great overall experience if one truly has a serverless use case. So, what makes an use case serverless in the end? It comes down to simple math in my opinion: when the traffic/requests of an app translate(s) to Lambda execution times whose summed monetized value is cheaper than the price of running that same app on a server.
I was able to achieve my goal of reducing the costs by 95% from $30 to $2 per month. The return on investment was already noticeable in the first month after the migration. Additionally, my developer experience improved a lot as I got access to better tooling that comes with the vendor lock-in, which I personally don’t mind.
Footnotes
-
AWS Lambda offers a configuration to keep a certain number of runtimes warm. Ultimately, this boils down to a server-like approach that might turn out to be more expensive than serverful. ↩
-
A lot of research has been invested recently into how to reduce the cold start-up time of Java, resulting in native container images that leave out the Java Virtual Machine (JVM) and hence make Java serverless-ready. ↩
-
For the sake of completeness I should mention that since April 2022 AWS provides the possibility to expose a Lambda function directly to the web via Function URLs, which equip Lambdas with HTTPS endpoints. However, this new service does not meet the standards of a secure enterprise level API web layer by design. ↩
-
I do have to note that the AWS SDK supports a Lambda call within a Lambda, AWS strongly advises against it though. If one wants to trigger a Lambda function after the execution of another one, one is urged to do so by using message brokers as Lambda triggers. ↩
-
Like the ones provisioned for microservice architectures on a Kubernetes cluster. ↩